Stack
About
The fintech market is heavily regulated. Every Payment Institution and E-Money Institution operating in Europe must be licensed and registered with a national authority. The European Banking Authority (EBA) consolidates all of these into a single public registry: EUCLID. The data is authoritative and machine-readable.
This project is an end-to-end agentic outbound pipeline that turns this regulatory data into a working outbound system. It ingests the EBA EUCLID registry, scores entities against GTM criteria, pushes shortlisted accounts to a CRM, and enriches them with AI before human review. The goal was not to build a one-off tool. It was to test whether a fully replicable and scalable outbound system could be assembled from scratch using modern AI tooling, on the same architectural model as the GTM system built at Numeral in 2022.
I followed nine principles for this project: auditability, API cost control, scalability, documented tool choices, multi-step runs with possible interruption, prompt versioning, GDPR, master data quality, real output.
None of them are new. None of what was built here is exceptionally novel. That is the point. What is exceptional is the capacity to execute, to scale, and to reproduce the process. That is what would have changed the game in 2022.
The story
The Euclid project existed already back in 2022. At Numeral, this work was done manually: scoring, processing hundreds of thousands of entities from the EUCLID regulatory file, preparing campaigns. It was a one-shot exercise each time, not a pipeline. Not something anyone could run twice without rebuilding it.
Four years later, in early 2026, agentic AI is everywhere. The question became: what would that work have looked like if Claude Code, Codex, and the n8n MCP had existed in 2022? Could it have been a system rather than a task?
That question became the project. It was built as part of the Lion programme by Maria Schools, a six-week intensive with a cohort designed to challenge the work at each stage. The soutenance, the final presentation to a panel, was in May 2026.
Output
The pipeline runs in nine steps, from raw regulatory data to a sent outbound message, with two mandatory human gates:
- W1 - Run start: a Python script initialises the run and creates a manifest JSON with a unique run ID, timestamp, and operator note. Every subsequent step writes back to this manifest.
- W2 - Normalisation and scoring: n8n calls the Anthropic API to normalise the raw EBA records, then scores each one against explicit rules per segment (e.g. SEPA-zone PI, SEPA-zone EMI). The full registry lists around 300,000 entities, of which approximately 1,500 are PI/EMIs with any GTM relevance at this stage of the project. The vast majority will never reach the CRM. Cost: $0.003 per 100 accounts cleaned and scored.
- W3 - CRM import: n8n pushes the shortlist to Attio via webhook. Companies are created or updated with their scores and segment classification.
- W4 - Enrichment: Claude Code researches each shortlisted company to add contacts, company size signals, and recent news.
- W5 - Enrichment push: Python script patches the Attio records with the enrichment data.
- Gate 1 - Human review: the operator reviews the shortlist in Attio and approves or blocks each account. Nothing moves forward without this step.
- W6 - Message generation: an n8n AI Agent (Claude Haiku) writes a personalised first-touch message for each approved contact, stored directly in Attio. The angle is selected automatically based on scoring signals.
- Gate 2 - Message review: the operator reads and approves each message before send. No email leaves without explicit sign-off.
- W7 - Feedback: outcomes are recorded back to the manifest. The loop closes.
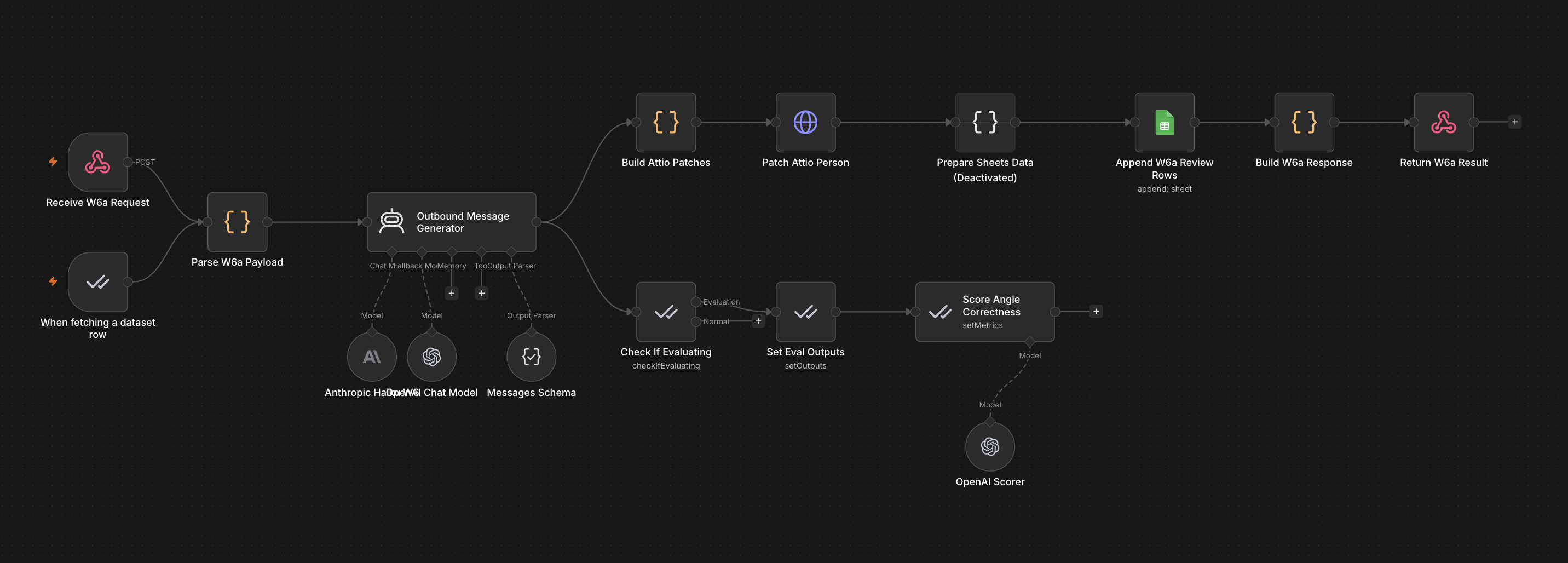
Everything in this pipeline is automatable end-to-end. The gates can be removed, the steps chained without human intervention. But that only makes sense once the process is fully mastered and the outputs are predictable. Automating an unpredictable process does not fix it. It just makes it fail faster and at scale.
This version deliberately excludes dedicated enrichment and outbound tools. That was a scope decision. At scale, third-party tools remain relevant: contact enrichment platforms provide data quality that a custom pipeline cannot match alone, and outbound sequencing tools handle deliverability, reply tracking, and volume in ways that a single-send setup cannot. Building the pipeline from first principles is the right starting point. Adding specialist tools on top is the right next step.
Learnings
The project started as a pure multi-agent system, with LLM reasoning at every step. It ended as something more disciplined: deterministic by default, agentic only where contextual judgement is genuinely irreplaceable. In the final architecture, only one step uses an AI Agent node: message generation. Every other step is a structured HTTP call with fixed logic and predictable output. That shift was not a compromise. It was the correct design.
The principle holds broadly: the more precisely a need is defined, the more deterministic the solution should be. Agentic components add power where the input space is too varied for rules. They add noise everywhere else. Placing them with restraint is a design decision, not a limitation. And the structure that makes restraint possible is the workflow itself.
Workflows are not dead. At every stage of the pipeline there is a trigger and an action. That trigger-action logic is precisely what organises the process and keeps the noise out. n8n handles orchestration, audit, and monitoring across the full run. Every step is visible, every transition is logged, and every failure is traceable. That auditability is what makes human-in-the-loop meaningful: the operator is not just approving outputs, they are reviewing a process they can inspect at any point.
For that structure to remain durable and scalable, the tooling layer needs to hold. Combining Claude Code and Codex to develop the project proved highly effective. Codex, at a lower cost and with a different underlying model, helped unblock obstacles and audit the project to verify end-to-end execution. Not depending on a single model also provides a practical safety net: in the event of an outage or an unplanned change in token pricing, there is a fallback ready.
Whatever the architectural choices, everything starts from input quality. That was the first challenge, and it came before any question of workflows or infrastructure. The EBA registry is inconsistent across countries: entity names vary, legal forms differ, and many records lack basic firmographic signals. The normalisation prompt required several iterations before output quality stabilised. Prompt versioning, applied from the start, made it possible to track exactly what changed between runs and why.
The same problem appeared in the scoring logic. Rules that feel intuitive in a sales context interact in non-obvious ways at scale. The definitions matter as much as the rules themselves. The first shortlist was technically correct but commercially weak. Tightening it required going back to first principles: what does a genuinely good PI/EMI prospect look like, and why.
Why it matters professionally
In 2022, I built Numeral’s outbound system from scratch: data sourcing, scoring, CRM routing, and sequencing, manually assembled and maintained. Euclid is the same system rebuilt with agents. The architecture is identical in intent: separate data normalisation, scoring logic, and outreach copy into independent modules. What changed is that each module is now driven by a model rather than a human. The human-in-the-loop gates remain deliberate. AI proposes. Humans approve. That boundary matters.
The value is not Euclid specifically. It is the proof that this kind of system, which took weeks to build in 2022, can now be assembled in days, on any target market, with any data source. n8n runs self-hosted on a personal VPS, which means owning the full orchestration layer rather than delegating it to a managed platform.